Github Repo | Full-code notebook
In this post, I will work my way into basic Sentiment Analysis methods and experiment with some techniques. I will use the data from the IMDB review dataset acquired from Kaggle.
We will be examining/going over the following:
- Data preprocessing for sentiment analysis
- 2 different feature representations:
- Sparse vector representation
- Word frequency counts
- Comparison using:
- Logistic regression
- Naive Bayes
Feature Representation
Your model will be, at most, as good as your data, and your data will be only as good as you understand them to be, hence the features. I want to see the most useless or naive approaches and agile methods and benchmark them for both measures of prediction success and for training and prediction time.
Before anything else, let’s load, organize and clean our data really quick:
| |
Let’s start with creating a proper and clean vocabulary that we will use for all the representations we will examine.
Clean Vocabulary
We just read all the words as a set, to begin with,
So for the beginning of the representation, we have 331.056 words in our vocabulary. This number is every non-sense included, though. We also didn’t consider any lowercase - uppercase conversion. So let’s clean these step by step.
We reduced the number from 331.056 to 84.757. We can do more. With this method, we encode every word we see in every form possible. So, for example, “called,” “calling,” “calls,” and “call” will all be a separate words. Let’s get rid of that and make them reduce to their roots. Here we start getting help from the dedicated NLP library NLTK since I don’t want to define all these rules myself (nor could I):
The last step towards cleaning will be to get rid of stopwords. These are ’end,’ ‘are,’ ‘is,’ etc. words in the English language.
Now that we have good words, we can set up a lookup table to keep encodings for each word.
Now we have a dictionary for every proper word we have in the data set. Therefore, we are ready to prepare different feature representations.
Since we will convert sentences in this clean form, again and again, later on, let’s create a function that combines all these methods:
| |
Ideally, we could initialize tokenizer stemmer and stop_words globally (or as a class parameter), so we don’t have to keep initializing.
Sparse Vector Representation
This will represent every word we see in the database as a feature… Sounds unfeasible? Yeah, it should be. I see multiple problems here. The main one we all think about is this is a massive vector for each sentence with a lot of zeros (hence the name). This means most of the data we have is telling us practically the same thing as the minor part; we have these words in this sentence vs. we don’t have all these words. Second, we are not keeping any correlation between words (since we are just examining word by word).
We go ahead and create a function for encoding every word for a sentence:
We then convert all the data we have using this encoding (in a single matrix):
That’s it for this representation.
Word Frequency Representation
This version practically reduces the 10.667 dimensions to 3 instead. We are going to count the number of negative sentences a word passes in as well as positive sentences. This will give us a table indicating how many positive and negative sentences a word has found in:
The next thing to do is to convert these enormous numbers into probabilities. There are multiple points to add here: First, we are getting the probability of this single word being in many positive and negative sentences, so the values will be minimal. Hence we need to use a log scale to avoid floating point problems. Second is, we might get words that don’t appear in our dictionary, which will have a likelihood of 0. Since we don’t want a 0 division, we add laplacian smoothing, like normalizing all the values with a small initial. Here goes the code:
After getting the frequencies and fixing the problems we mentioned, we now define the new encoding method for this version of the features
We end by converting our data as before
Let’s take a sneak peek at what our data looks like:
| |
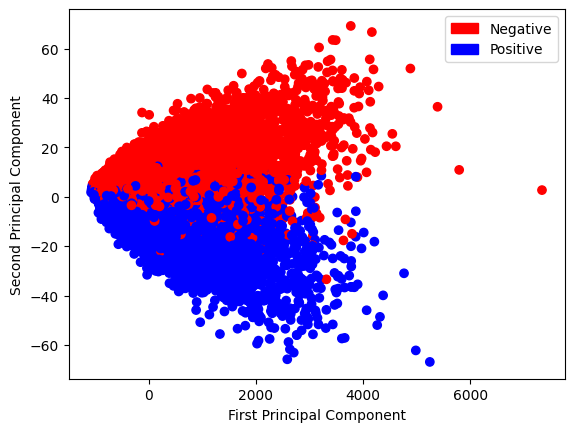
A better would be to use PCA for this kind of representation, but for now, we will ignore that fact since we want to explore that in episode 2.
Model Development
This episode mainly focuses on cleaning the data and developing decent representations. This is why I will only include Logistic Regression for representation comparison, we then can compare Naive Bayes and Logistic Regression to pick a baseline for ourselves.
Logistic Regression
Logistic regression is a simple single-layer network with sigmoid activation. This is an excellent baseline as it is one of the simplest binary classification methods. I am not explaining this method in depth, so if you want to learn more, please do so. I will use a simple PyTorch implementation.
We then define the loss function and the optimizer to use. I am using Binary Cross Entropy for the loss function and Adam for the optimization with a learning rate of 0.01.
| |
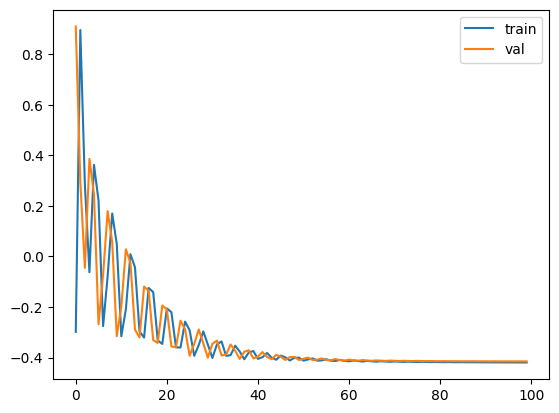
Sparse Representation Training We first start with training the sparse representation. I trained for 100 epochs and reached 0.614 training accuracy and 0.606 validation accuracy. Here is the learning curve
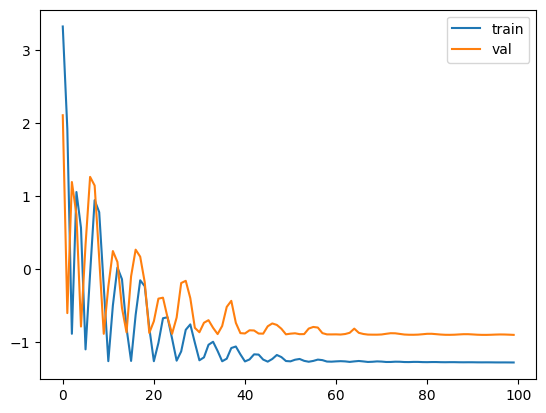
Word Frequency Representation Training I trained using the same parameter settings above, reaching 0.901 training accuracy and 0.861 validation accuracy. Here is the learning curve in the log scale
Naive Bayes
The next really good baseline is Naive Bayes. This is a very simple model that is very fast to train and has a very good accuracy. Naive Bayes is a probabilistic model that uses Bayes’ theorem to calculate the probability of a class given the input. The main assumption of this model is that the features are independent of each other. This is why it is called Naive. To give a basic intuition of how this model works, let’s say we have a sentence I love this movie and we want to classify it as positive or negative. We first calculate the probability of the sentence being positive and negative using the conditional frequency probability we calculated above and multiply them by the prior probability of the class. The class with the highest probability is the predicted class.
To put it in other terms, this is the Bayes Rule:
$$P(C|X) = \frac{P(X|C)P(C)}{P(X)}$$
We then calculate $P(w_i|pos)$ and $P(w_i|neg)$ for each word in the sentence where $w_i$ is the $i^{th}$ word in the sentence and $pos$ and $neg$ are the positive and negative classes respectively. We then multiply the ratio of these, so:
$$\prod_{i=1}^{n} \frac{P(w_i|pos)}{P(w_i|neg)}$$
If the result is greater than 1, we predict the sentence to be positive, otherwise negative. When we convert this to log space and add the log prior, we get the Naive Bayes equation:
$$\log \frac{P(pos)}{P(neg)} + \sum_{i=1}^{n} \log \frac{P(w_i|pos)}{P(w_i|neg)}$$
We now implement this in python and numpy.
| |
Here we recreate the frequency table as lambda_ and converting the counts to frequencies as well as log likelihood. So we have a self containing naive bayes method.
We then test and get 0.9 for training accuracy and 0.859 for test accuracy.
| |
So we got pretty much the same exact result as Logistic regression. The upside of Naive Bayes is that it is very fast to train and has a very good accuracy. The downside is that it is not very flexible and does not capture the relationship between the features. This is why we use more complex models like Neural Networks. Later on I might have another post on more mature methods.
Comments
Comments